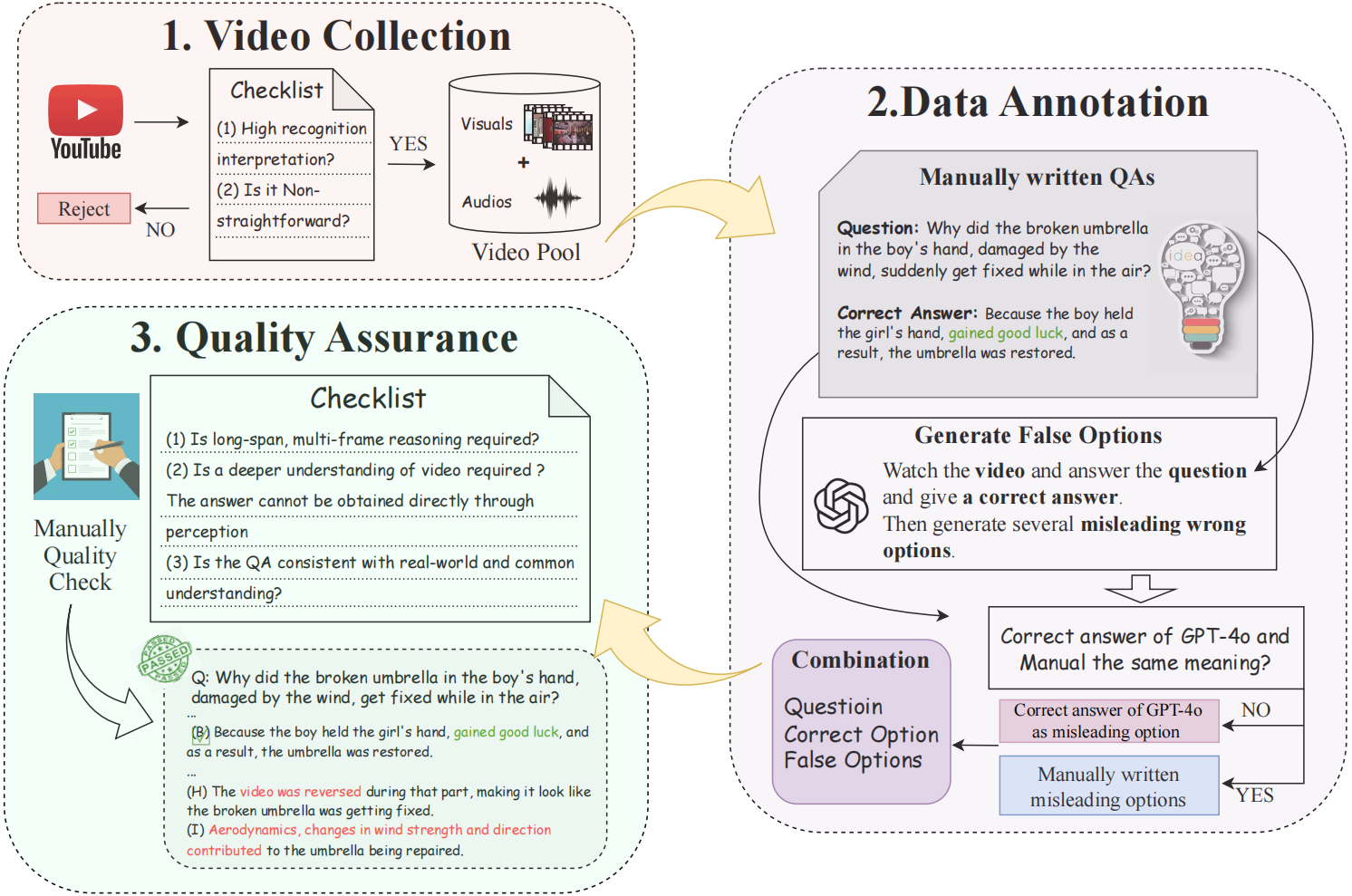
📢 The leaderboard is constantly updating as we are welcoming new submissions!
We consider two test settings: w/o CoT and w/ CoT.
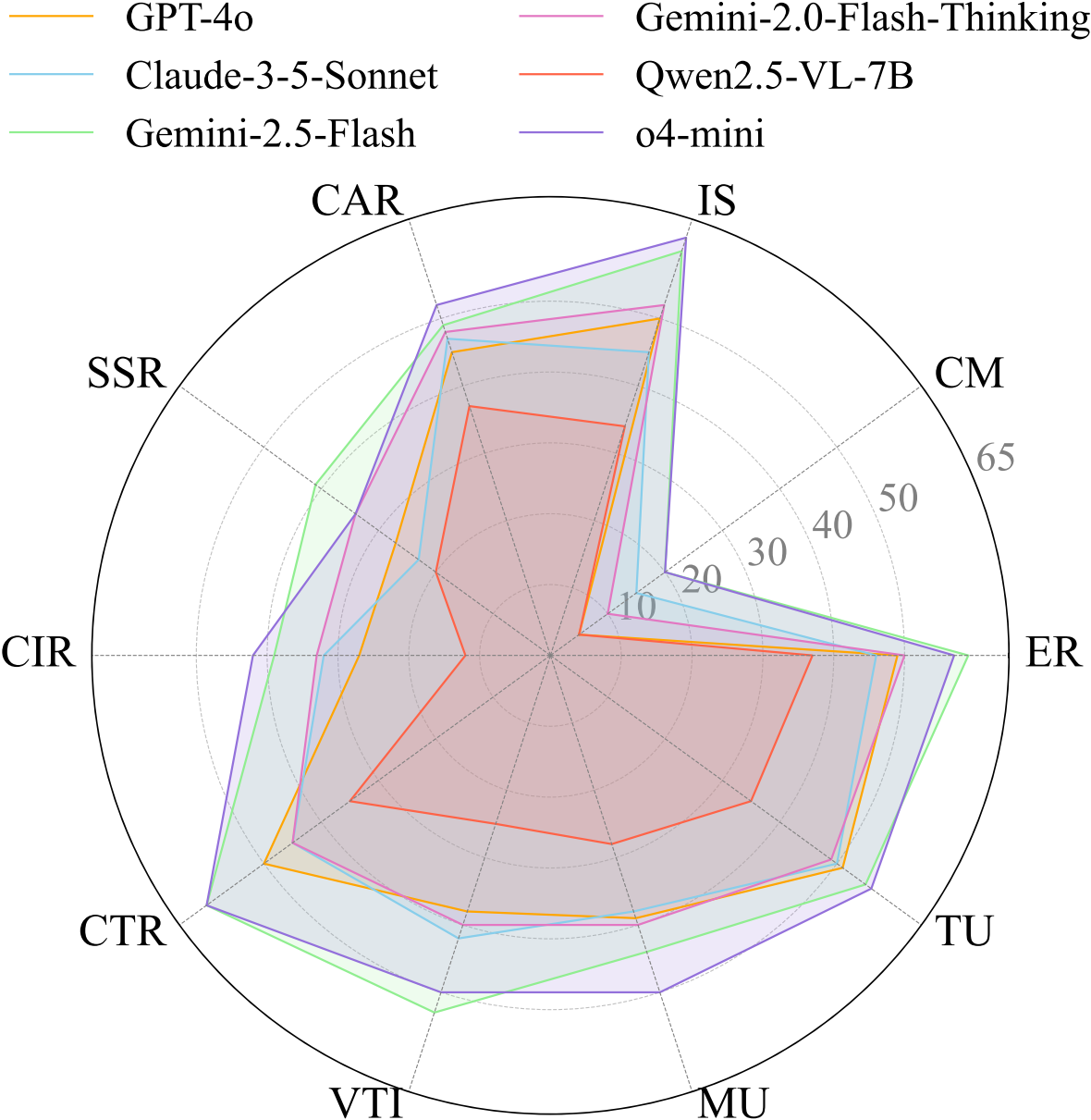
This leaderboard is sorted by the overall accuracy w/o CoT. The CoT results are obtained using CoT prompt. To view other sorted results, please click on the corresponding cell.
| # | Model | Overall (%) | Implicit (%) | Explicit (%) | Video Categories | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| w/o CoT | w/ CoT | w/o CoT | w/ CoT | w/o CoT | w/ CoT | Art | Life | TV | Film | Film | Phi. | ||
| Human | 86.0 | 86.0 | 80.6 | 80.6 | 91.2 | 91.2 | 57.7 | 92.3 | 90.6 | 92.3 | 90.7 | 70.0 | |
| o4-mini-2025-04-16
OpenAI |
52.5 | 52.1 | 54.6 | 47.1 | 46.0 | 48.2 | 40.1 | 54.0 | 54.0 | 51.7 | 65.3 | 27.9 | |
| Gemini-2.5-Flash
|
51.2 | 50.5 | 52.9 | 52.3 | 46.9 | 45.3 | 45.3 | 39.5 | 50.3 | 47.9 | 65.6 | 34.9 | |
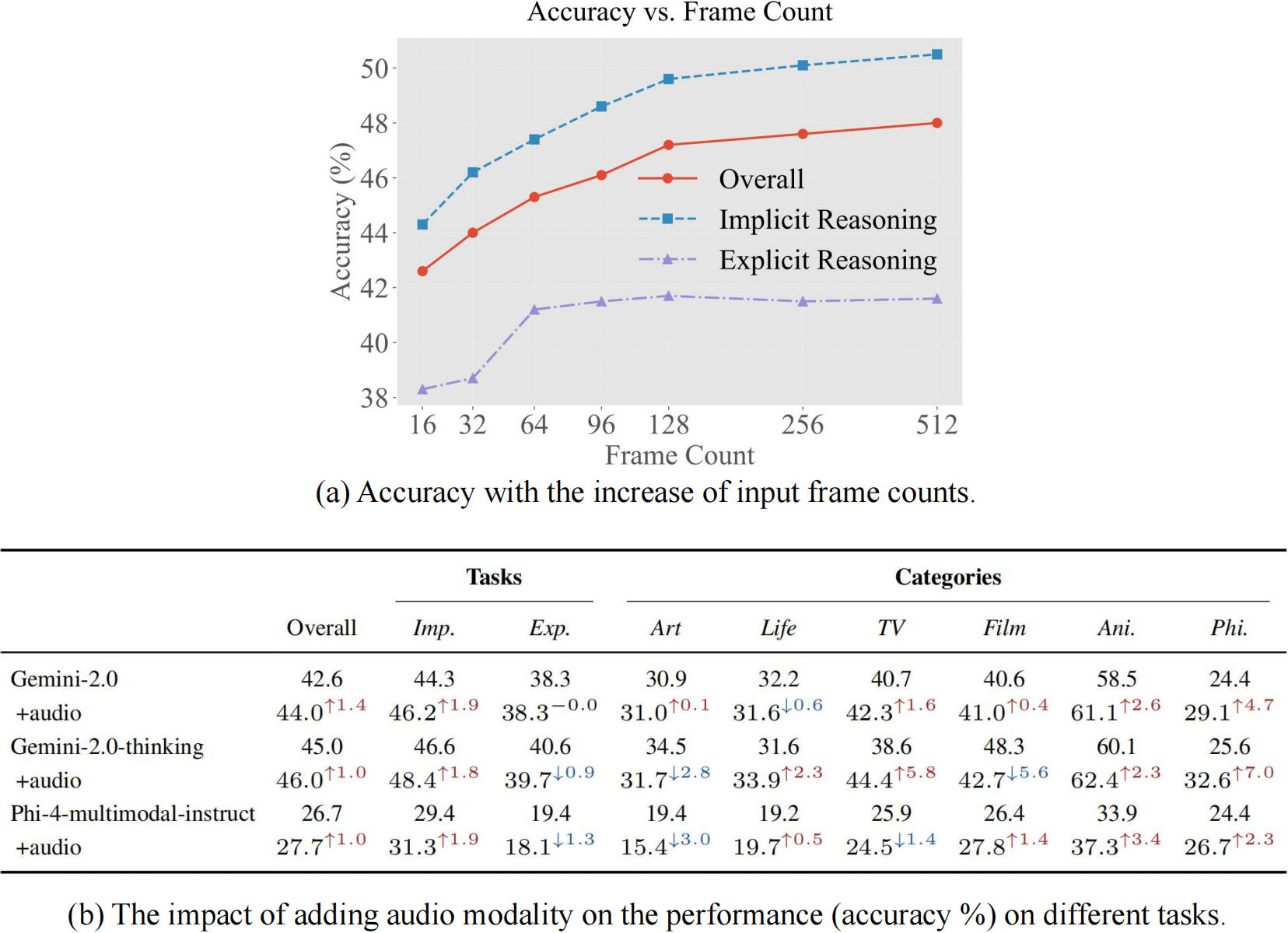
| Gemini-2.0-Flash (512 frames)
|
48.0 | 49.9 | 50.5 | 52.6 | 41.6 | 42.9 | 36.7 | 36.7 | 39.7 | 46.2 | 66.7 | 31.4 | |
| GPT-4.1-2025-04-14
OpenAI |
46.6 | 48.9 | 49.1 | 51.7 | 40.3 | 41.7 | 43.2 | 35.6 | 43.9 | 46.5 | 57.1 | 34.9 | |
| Gemini-2.0-Flash-thinking
|
45.0 | 43.5 | 46.6 | 46.0 | 40.6 | 37.1 | 34.5 | 31.6 | 38.6 | 48.3 | 60.1 | 25.6 | |
| GPT-4o-2024-11-20
OpenAI |
44.0 | 46.1 | 46.6 | 46.9 | 37.6 | 44.0 | 38.1 | 37.3 | 34.9 | 41.0 | 61.6 | 32.6 | |
| Claude-3.5-Sonnet-20241022
Anthropic |
43.3 | 44.2 | 45.0 | 46.1 | 38.9 | 39.1 | 33.8 | 31.1 | 41.3 | 41.3 | 55.8 | 44.4 | |
| Gemini-2.0-Flash (16 frames)
|
42.6 | 44.3 | 44.3 | 45.9 | 38.3 | 40.0 | 30.9 | 32.2 | 40.7 | 40.6 | 58.5 | 24.4 | |
| Gemma-3-27b-it
|
42.0 | 41.1 | 46.5 | 44.7 | 30.3 | 32.0 | 31.7 | 32.2 | 35.5 | 41.3 | 56.1 | 33.7 | |
| InternVL2.5-38B
Shanghai AI Lab |
39.9 | 39.7 | 43.8 | 43.7 | 29.9 | 29.4 | 30.4 | 28.8 | 30.4 | 37.2 | 57.4 | 29.1 | |
| Qwen2.5-VL-72B
Alibaba |
39.1 | 40.4 | 41.3 | 42.8 | 33.4 | 34.3 | 28.9 | 28.2 | 29.1 | 36.5 | 55.6 | 37.2 | |
| GPT-4o-mini-2024-07-18
OpenAI |
34.8 | 35.2 | 38.0 | 38.6 | 26.3 | 26.3 | 29.5 | 25.4 | 29.6 | 33.0 | 48.7 | 18.6 | |
| Gemma-3-12b-it
|
34.0 | 34.2 | 37.8 | 37.6 | 24.0 | 25.4 | 19.4 | 24.9 | 25.9 | 31.3 | 51.9 | 24.4 | |
| InternVL3-8B
Shanghai AI Lab |
33.6 | 32.9 | 35.5 | 33.4 | 28.6 | 31.4 | 23.0 | 22.6 | 31.7 | 24.3 | 52.9 | 23.2 | |
| Qwen2.5-VL-7B
Alibaba |
30.1 | 32.4 | 33.7 | 36.2 | 20.8 | 22.5 | 20.9 | 18.1 | 29.6 | 21.2 | 48.4 | 19.8 | |
| Phi-4-multimodal-instruct
Microsoft |
26.7 | 27.6 | 29.4 | 31.2 | 19.4 | 18.1 | 19.4 | 19.2 | 25.9 | 26.4 | 33.9 | 24.4 | |
| Cogvlm2-video-llama3
THUDM |
25.6 | 26.1 | 25.4 | 26.2 | 26.1 | 25.7 | 15.5 | 18.3 | 24.7 | 19.1 | 43.2 | 20.8 | |
| NVILA-8B-Video
NVIDIA |
25.5 | 25.3 | 26.2 | 24.2 | 23.9 | 25.9 | 17.3 | 21.3 | 23.5 | 21.6 | 38.0 | 21.8 | |
| LLaVA-Video
Bytedance & NTU S-Lab |
18.4 | 17.6 | 19.1 | 18.1 | 15.4 | 16.3 | 14.4 | 11.2 | 13.2 | 17.4 | 21.4 | 12.8 | |
| LLaVA-Onevision
Bytedance & NTU S-Lab |
6.5 | 8.8 | 7.0 | 9.6 | 5.4 | 6.6 | 6.5 | 3.4 | 9.5 | 3.8 | 9.8 | 1.2 | |
Last Update: 2025-05-15